Output Files¶
The pVACseq pipeline will write its results in separate folders depending on which prediction algorithms were chosen:
MHC_Class_I: for MHC class I prediction algorithmsMHC_Class_II: for MHC class II prediction algorithmscombined: If both MHC class I and MHC class II prediction algorithms were run, this folder combines the neoeptiope predictions from both
Each folder will contain the same list of output files (listed in the order created):
| File Name | Description |
|---|---|
<sample_name>.tsv |
An intermediate file with variant, transcript, coverage, vaf, and expression information parsed from the input files. |
<sample_name>.tsv_<chunks> (multiple) |
The above file but split into smaller chunks for easier processing with IEDB. |
<sample_name>.all_epitopes.tsv |
A list of all predicted epitopes and their binding affinity scores, with
additional variant information from the <sample_name>.tsv. |
<sample_name>.filtered.tsv |
The above file after applying all filters, with cleavage site and stability predictions added. |
<sample_name>.filtered.condensed.ranked.tsv |
A condensed version of the filtered TSV with only the most important columns remaining, with a priority score for each neoepitope candidate added. |
all_epitopes.tsv and filtered.tsv Report Columns¶
| Column Name | Description |
|---|---|
Chromosome |
The chromosome of this variant |
Start |
The start position of this variant in the zero-based, half-open coordinate system |
Stop |
The stop position of this variant in the zero-based, half-open coordinate system |
Reference |
The reference allele |
Variant |
The alt allele |
Transcript |
The Ensembl ID of the affected transcript |
Transcript Support Level |
The transcript support level (TSL)
of the affected transcript. NA if the VCF entry doesn’t contain TSL information. |
Ensembl Gene ID |
The Ensembl ID of the affected gene |
Variant Type |
The type of variant. missense for missense mutations, inframe_ins for
inframe insertions, inframe_del for inframe deletions, and FS for frameshift variants |
Mutation |
The amnio acid change of this mutation |
Protein Position |
The protein position of the mutation |
Gene Name |
The Ensembl gene name of the affected gene |
HGVSc |
The HGVS coding sequence variant name |
HGVSp |
The HGVS protein sequence variant name |
HLA Allele |
The HLA allele for this prediction |
Peptide Length |
The peptide length of the epitope |
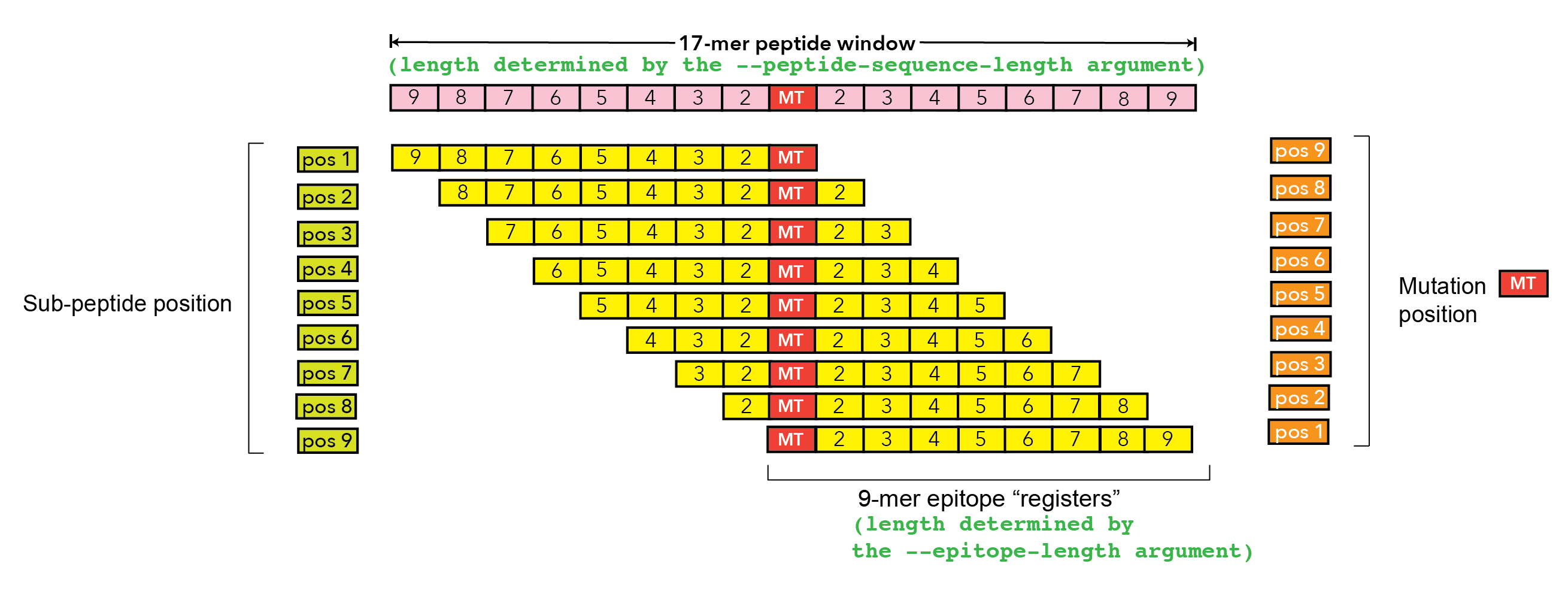
Sub-peptide Position |
The one-based position of the epitope within the protein sequence used to make the prediction |
Mutation Position |
The one-based position of the start of the mutation within the epitope sequence. 0 if the
start of the mutation is before the epitope |
MT Epitope Seq |
The mutant epitope sequence |
WT Epitope Seq |
The wildtype (reference) epitope sequence at the same position in the full protein sequence. NA if there is no wildtype sequence at this position or if more than half of the amino acids of the mutant epitope are mutated |
Best MT Score Method |
Prediction algorithm with the lowest mutant ic50 binding affinity for this epitope |
Best MT Score |
Lowest ic50 binding affinity of all prediction algorithms used |
Corresponding WT Score |
ic50 binding affinity of the wildtype epitope. NA if there is no WT Epitope Seq. |
Corresponding Fold Change |
Corresponding WT Score / Best MT Score. NA if there is no WT Epitope Seq. |
Tumor DNA Depth |
Tumor DNA depth at this position. NA if VCF entry does not contain tumor DNA readcount annotation. |
Tumor DNA VAF |
Tumor DNA variant allele frequency (VAF) at this position. NA if VCF entry does not contain
tumor DNA readcount annotation. |
Tumor RNA Depth |
Tumor RNA depth at this position. NA if VCF entry does not contain tumor RNA readcount annotation. |
Tumor RNA VAF |
Tumor RNA variant allele frequency (VAF) at this position. NA if VCF entry does not contain
tumor RNA readcount annotation. |
Normal Depth |
Normal DNA depth at this position. NA if VCF entry does not contain normal DNA readcount annotation. |
Normal VAF |
Normal DNA variant allele frequency (VAF) at this position. NA if VCF entry does not contain
normal DNA readcount annotation. |
Gene Expression |
Gene expression value for the annotated gene containing the variant. NA if VCF entry does not contain
gene expression annotation. |
Transcript Expression |
Transcript expression value for the annotated transcript containing the variant. NA if VCF entry does
not contain transcript expression annotation. |
Median MT Score |
Median ic50 binding affinity of the mutant epitope across all prediction algorithms used |
Median WT Score |
Median ic50 binding affinity of the wildtype epitope across all prediction algorithms used.
NA if there is no WT Epitope Seq. |
Median Fold Change |
Median WT Score / Median MT Score. NA if there is no WT Epitope Seq. |
Individual Prediction Algorithm WT and MT Scores (multiple) |
ic50 scores for the MT Epitope Seq and WT Eptiope Seq for the individual prediction algorithms used |
cterm_7mer_gravy_score |
Mean hydropathy of last 7 residues on the C-terminus of the peptide |
max_7mer_gravy_score |
Max GRAVY score of any kmer in the amino acid sequence. Used to determine if there are any extremely hydrophobic regions within a longer amino acid sequence. |
difficult_n_terminal_residue (T/F) |
Is N-terminal amino acid a Glutamine, Glutamic acid, or Cysteine? |
c_terminal_cysteine (T/F) |
Is the C-terminal amino acid a Cysteine? |
c_terminal_proline (T/F) |
Is the C-terminal amino acid a Proline? |
cysteine_count |
Number of Cysteines in the amino acid sequence. Problematic because they can form disulfide bonds across distant parts of the peptide |
n_terminal_asparagine (T/F) |
Is the N-terminal amino acid a Asparagine? |
asparagine_proline_bond_count |
Number of Asparagine-Proline bonds. Problematic because they can spontaneously cleave the peptide |
Best Cleavage Position (optional) |
Position of the highest predicted cleavage score |
Best Cleavage Score (optional) |
Highest predicted cleavage score |
Cleavage Sites (optional) |
List of all cleavage positions and their cleavage score |
Predicted Stability (optional) |
Stability of the pMHC-I complex |
Half Life (optional) |
Half-life of the pMHC-I complex |
Stability Rank (optional) |
The % rank stability of the pMHC-I complex |
NetMHCstab allele (optional) |
Nearest neighbor to the HLA Allele. Used for NetMHCstab prediction |
filtered.condensed.ranked.tsv Report Columns¶
| Column Name | Description |
|---|---|
Gene Name |
The Ensembl gene name of the affected gene. |
Mutation |
The amino acid change of this mutation. |
Protein Position |
The protein position of the mutation. |
HGVSc |
The HGVS coding sequence name. |
HGVSp |
The HGVS protein sequence name. |
HLA Allele |
The HLA allele for this prediction. |
Mutation Position |
The one-based position of the start of the mutation within the epitope sequence. 0 if the
start of the mutation is before the epitope |
MT Epitope Seq |
Mutant epitope sequence. |
Median MT Score |
Median ic50 binding affinity of the mutant epitope across all prediction algorithms used |
Median WT Score |
Median ic50 binding affinity of the wildtype epitope across all prediction algorithms used.
NA if there is no WT Epitope Seq. |
Median Fold Change |
Median WT Score / Median MT Score. NA if there is no WT Epitope Seq. |
Best MT Score |
Lowest ic50 binding affinity of all prediction algorithms used |
Corresponding WT Score |
ic50 binding affinity of the wildtype epitope. NA if there is no WT Epitope Seq. |
Corresponding Fold Change |
Corresponding WT Score / Best MT Score. NA if there is no WT Epitope Seq. |
Tumor DNA Depth |
Tumor DNA depth at this position. NA if VCF entry does not contain tumor DNA readcount annotation. |
Tumor DNA VAF |
Tumor DNA variant allele frequency at this position. NA if VCF entry does not contain tumor DNA readcount annotation. |
Tumor RNA Depth |
Tumor RNA depth at this position. NA if VCF entry does not contain tumor RNA readcount annotation. |
Tumor RNA VAF |
Tumor RNA variant allele frequency at this position. NA if VCF entry does not contain tumor RNA readcount annotation. |
Gene Expression |
Gene expression value at this position. NA if VCF entry does not contain gene expression annotation. |
Rank |
A priority rank for the neoepitope (best = 1). |
The pVACseq Neoeptiope Priority Rank¶
Each of the following 4 criteria are assigned a rank-ordered value (worst = 1):
- B = Rank of the mutant IC50 binding affinity, with the lowest being the best.
If the
--top-score-metricis set tomedian(default) theMedian MT Scoreis used. If it is set tolowesttheBest MT Scoreis used. - F = Rank of
Fold Changebetween MT and WT alleles, with the highest being the best. - M = Rank of mutant allele expression, calculated as (
Gene Expression*Tumor RNA VAF), with the highest being the best. - D = Rank of
Tumor DNA VAF, with the highest being the best.
A score is calculated from the above ranks with the following formula: B + F + (M * 2) + (D / 2). This score is then converted to a rank (best = 1).
Note
The pVACseq rank calculation detailed above is just one of many ways to prioritize neoeptiope candidates. The body of evidence in this area is still incomplete, and the methodology of ranking is likely to change substantially in future releases. While we have found this ranking useful, it is not a substitute for careful curation and validation efforts.