Usage¶
The pVACtools Output section of the pVACview user interface menu has three sections:
Upload
Visualize and Explore
Export
Additionally, the menu also has links to:
Tutorials, where the pVACview app is documented in more detail
pVACview Documentation, which is a link to the documentation here
Submit GitHub Issue, which is a link to GitHub to submit bug reports and additional questions
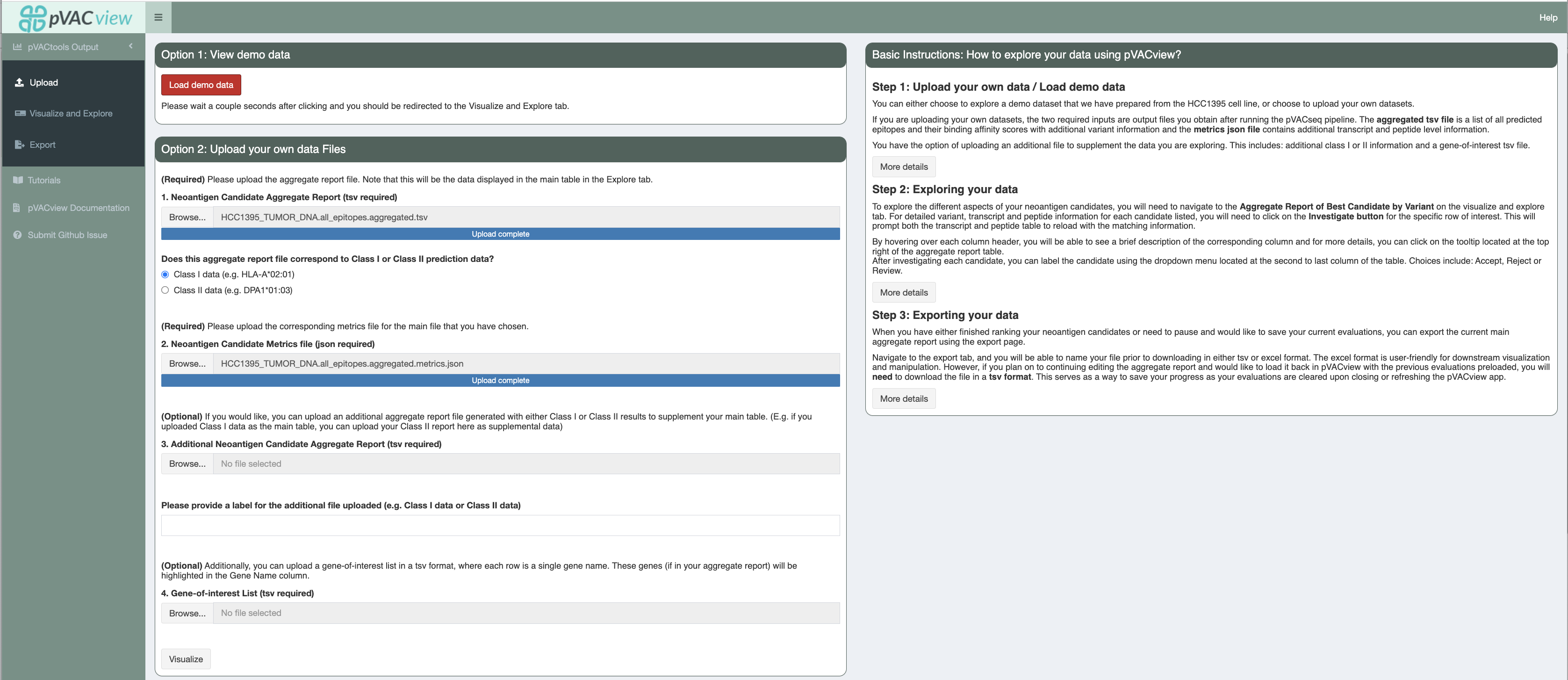
Upload¶
Once you’ve successfully launched pVACview by completing the prerequisites section, you can now upload your data by browsing through
your local directories to load in the aggregate report and metrics files, usually located in the same directory as your app.R file.
You will need to select the type of your files uploaded (Class I or Class II).
The two required inputs are <sample_name>.all_epitopes.aggregated.tsv and <sample_name>.all_epitopes.aggregated.metrics.json, both of which are output files from the pVACseq pipeline. The aggregated TSV file is a list of all predicted epitopes and their binding affinity scores,
with additional variant information and the metrics json file contains additional transcript and peptide level information that is needed for certain features of the pVACview application. You can find further details on them here.
You have the option of uploading an additional file to supplement the data you are exploring. This is useful in cases where you are visualizing Class I prediction data but would like to have a general idea of the variant’s Class II prediction performance or vice versa. In order to match your main data with data from your additional file, it is important that they were generated from the same set of variants (but predicted for different HLA alleles). You will also want to specify whether the type of data you are adding was generated from Class I or Class II on the upload page by selecting the appropriate radio button option.
We also provide users with the opportunity of uploading a gene-of-interest TSV file, where each individual line consists of one gene name. If matched in the aggregate report, the gene name will be highlighted using bold font and a green box around the cell.
Demo Data¶
Alternatively to using your own pVACseq data, users may test out the pVACview functionality by loading a set of demo data files using the “Load demo data” button.
The demo data was generated using the HCC1395 breast cancer cell line and a matched normal lymphoblastoid cell line HCC1395BL. All input files can be downloaded from GitHub. The demo data can be re-generated by running the following pVACseq command:
pvacseq run \
HCC1395_inputs/annotated.expression.vcf.gz \
HCC1395_TUMOR_DNA \
HLA-A*29:02,HLA-A*29:02,HLA-B*45:01,HLA-B*82:02,HLA-C*06:02,HLA-C*06:02,DQA1*03:03,DQA1*03:03,DQB1*03:02,DQB1*03:02,DRB1*04:05,DRB1*04:05 \
all \
HCC1395_outputs \
-e1 8,9,10,11 \
-e2 12,13,14,15,16,17,18 \
--normal-sample-name HCC1395_NORMAL_DNA \
-p HCC1395_inputs/phased.vcf.gz \
--pass-only \
--use-normalized-percentiles \
--allele-specific-binding-thresholds \
--allele-specific-anchors \
--run-reference-proteome-similarity \
--peptide-fasta HCC1395_inputs/Homo_sapiens.GRCh38.pep.all.fa.gz \
--problematic-amino-acids C \
--iedb-install-directory /opt/iedb \
-k -t 8
The pVACview demo data loads the MHC Class I aggregated report and matched metrics.json file as well as the MHC Class II aggregated report as the Additional Neoantigen Candidate Aggregate Report. It also loads a cancer Gene-of-interest List which is available on GitHub.
Please note that the parameters used for generating the pVACview demo data do not necessarily reflect the recommended or gold standard way of running pVACseq. While many of the chosen parameters are sensible options for many use cases, the parameters where primarily chosen to generate demo data that would demonstrate a wide variety of pVACview features. The parameter set that may be most useful for a user’s run is highly dependent on their exact use case. Please see our course for a deeper discussion on available parameters.
Visualize and Explore¶
Data¶
Upon successfully uploading the matching data files, you can now explore the different aspects of your neoantigen candidates.
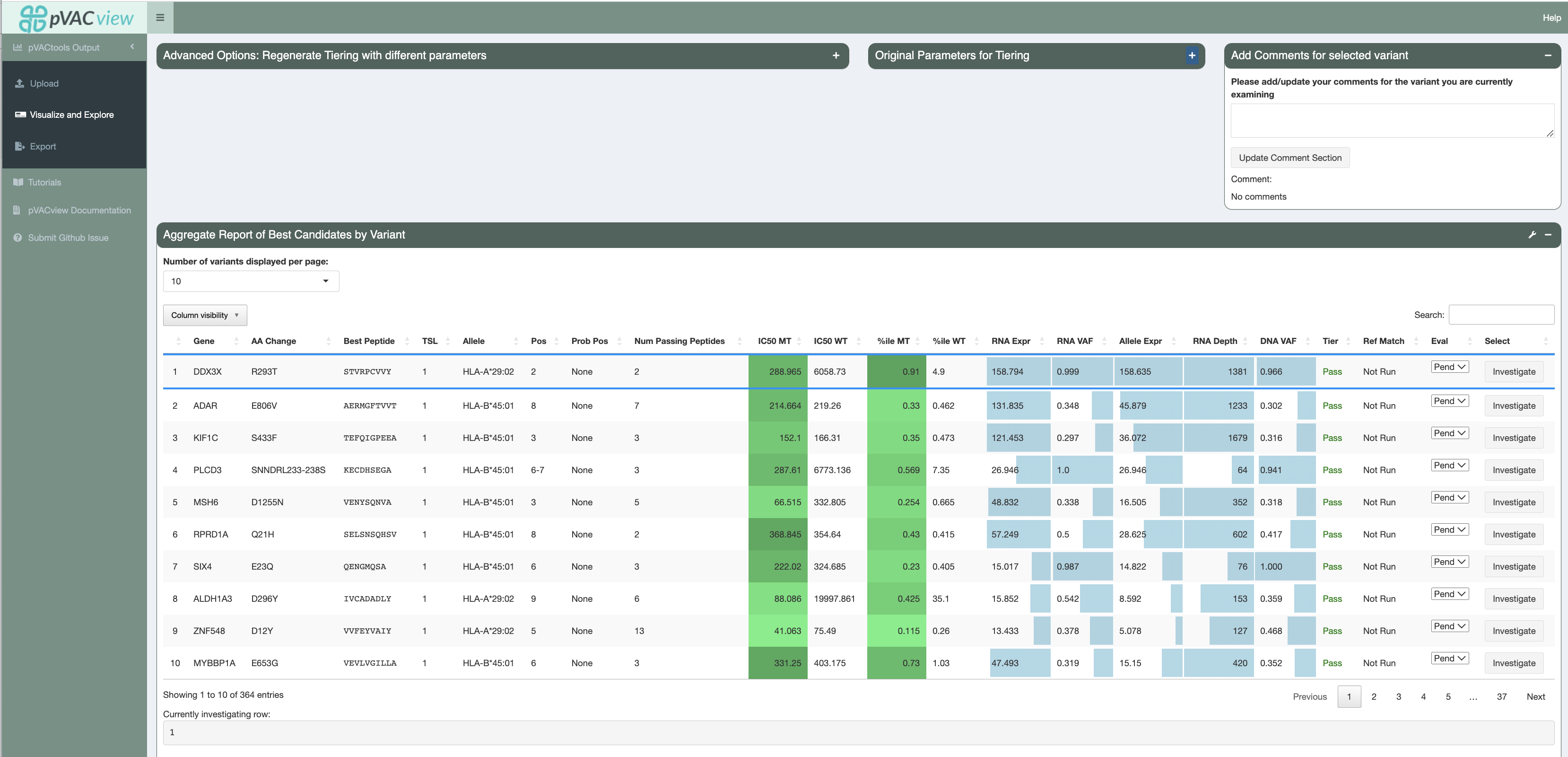
Specifically, the features can be separated into five categories:
Variant level information (Aggregate Report of Best Candidate by Variant panel)
The table in the Aggregate Report of Best Candidate by Variant panel showcases best neoantigen candidates by variant
Selected Variant detail information (Variant Information panel)
The Transcript Sets of Selected Variant tab lists the transcript sets for the variant selected in the in the main aggregate report table. A transcript set summarizes all transcripts that code for the same set of neoantigen candidates. The transcript set that includes the best transcript is highlighted in green and selected by default.
The Reference Matches tab lists reference proteome match details for the selected variant (if reference proteome similarity feature was originally run)
The Additional Data tab list additional information about the of the selected variant when a Additional Neoantigen Candidate Aggregate Report was uploaded.
Variant & Gene Info section lists VAF and expression information for the selected variant.
Selected Transcript Set information (certain tabs in the Transcript and Peptide Set Data panel)
The Transcripts in Set tab lists the Transcripts of selected set that produce good binding peptides.
It also includes the Expression, MANE Select status, Canonical status, Transcript Support Level, Biotypes, CDS Flags, and Transcript Length information of the transcripts in the set.
Selected Transcript Set Peptide information (certain tabs in the Transcript and Peptide Set Data panel)
The Peptide Candidates from Selected Transcript Set list all included peptides in the selected transcript set. The best peptide is highlighted in green.
It also includes the MHC binding prediction scores for each MT and WT peptide pair.
Lastly, it lists the mutation position, problematic amino acid positions, and anchor status of each peptide.
The Anchor Heatmap tab visualizes allele-specific anchor predictions using heatmaps and per-position and per-allele anchor weights.
Selected Peptide information (Additional Peptide Information panel)
The Binding Data tab shows per-algorithm and HLA-allele MHC binding predictions for the selected peptide and its matched WT (IC50 and Percentile).
The IC50 Plot and %ile Plot tabs shows violin plots for the IC50 and Percentile predictions, respectively.
The Elution and Immunogenicity Data tab shows presentation and immunogencity predictions.
For detailed descriptions on individual sections, please refer to features page.
Regenerate Tiering¶
Additionally, you can regenerate the Tiers of variants by supplying a different set of parameter cutoffs from your original pVACseq run and pressing the Recalculate Tiering with new parameters button:
Allele-specific anchor calculations
Check this box to turn on allele-specific anchor calculations. If this option is unchecked, the following positions will be considered anchor positions: 1, 2, n-1, and n
Anchor contribution cutoff
When the allele-specific anchor calculations option is chose, this is the contribution cutoff for determining which positions of an HLA allele are categorized as anchors. Previously, our lab has computationally predicted anchor positions for different hla alleles and peptide length combinations (“Accurate neoantigen prediction depends on mutation position relative to patient allele-specific MHC anchor location”). These predictions are normalized probabilities representing the likelihood of each position of the peptide to participate in anchoring to the HLA allele. Upon the user specifying the contribution cutoff, the application calculates which positions will be included such that their probabilities add up to equal/more than the specified cutoff. (For example: if positions 2 and 9 have normalized probabilities of 0.4 and 0.5 and the user specified the cutoff to be 0.8 , the anchors will be set as 2 and 9 for the specific peptide-HLA combination)
Binding Threshold
The threshold to consider a peptide a good binder. The IC50 MT will need to be below this value.
Allele-specific binding thresholds
When this box is checked, use allele-specific binding thresholds, as defined by IEDB, instead of the binding threshold set above. For alleles where not specific threshold is defined, the binding threshold set above is used as a fallback.
Binding Percentile Threshold
Additional threshold to consider when determining whether the peptide is a good binder. The IC50 %ile MT will need to be below this value.
Presentation Percentile Threshold
Threshold to consider when determining whether the peptide has good presentation The Pres %ile MT will need to be below this value.
Immunogenicity Percentile Threshold
Threshold to consider when determining whether the peptide has good imunogenicity The IM %ile MT will need to be below this value.
Percentile Threshold Strategy
This parameter determines how exactly to evaluate the binding threshold, binding percentile threshold, presentation percentile threshold, and immunogenicity percentile threshold. If it is set to “conservative”, the peptide needs to meet all thresholds in order to pass. If it is set to “exploratory”, it will only need to meet one of the thresholds to pass.
Clonal variant VAF
This is the estimated DNA VAF of the clonal variant of the tumor. Variants with a DNA VAF less than half the specified number will be marked as subclonal.
Allele Expression
Allele expression is calculated as gene expression * RNA VAF. This expression value is used as a cutoff in order to determine whether the peptide has good allele expression when the Allele Expr value of a variant is above this cutoff. also need to be below this value in order for
Transcript Prioritization Strategy
Specify the list of criteria to evaluate to determine whether or not the Best Transcript is a good transcript. If “canonical” is in the list, check whether the Canonical value is True. If “mane_select” is in the list, check whether the MANE Select value is True. If “tsl” is in the list, check whether the TSL value meets the Maximum Transcript Support Level cutoff. The Best Transcript needs to pass at least one of the specified criteria in order to be considered a good transcript.
Maximum Transcript Support Level
The threshold to use for evaluating a transcript on itse Ensembl transcript support level (TSL).
Top Score Sorting Metric
Specify the metric that should be used as the primary sort criteria for sorting candidates within each tier.
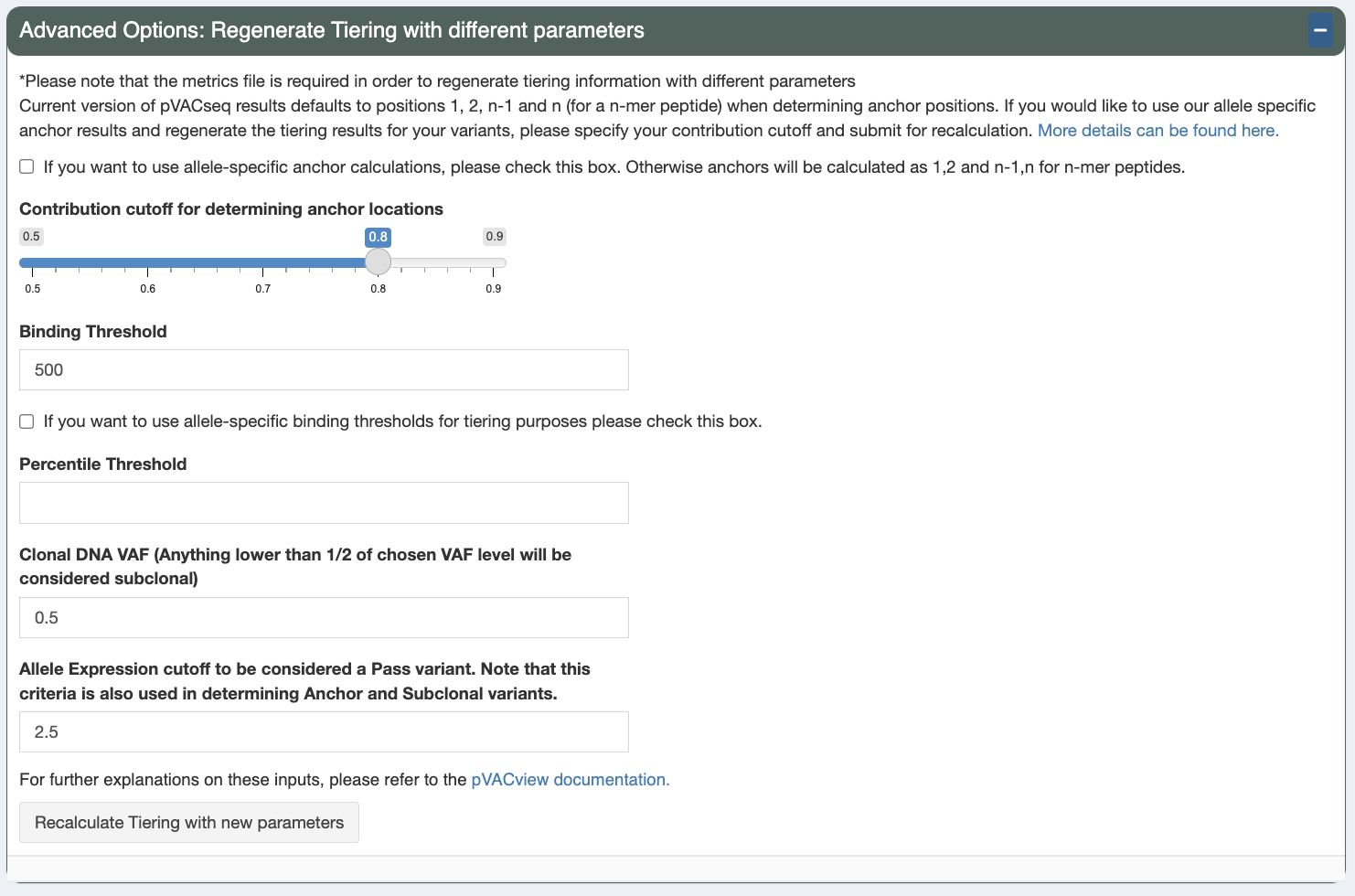
These parameters will default to the value used in your original pVACseq run.
After adjusting and retiering your candidates, the currently applied tiering
parameters are displayed in the Current Parameters for Tiering section.
The parameters originally used for tiering are displayed in the Original
Parameters for Tiering section. You can reset the tiers to the parameters
used originally by clicking the Reset to original parameters button.
Investigating Different Variants¶
To investigate a specific variant in detail (on both the transcript and peptide levels), you will need to click on
the candidate’s row in the main aggregate report table. Afterwards, you may choose to select a rating for the
neoantigen candidate using the three buttons on the right of the candidate’s row. By default, all peptides are initially in a Pending state when the report is generated from pVACseq. Based on
exploration and evaluation of the features provided, one of the buttons is selected. You can mark the peptide as
either “Accept” (thumbs-up button), “Reject” (thumbs-down button), or “Review” (flag button). Your current state of
selections are also counted and shown in the Peptide Evaluation Overview box.
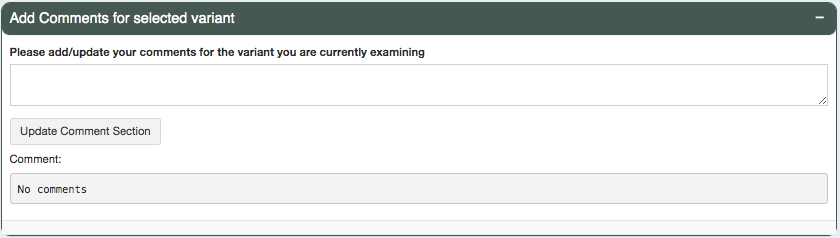
Users can add comments to each line of variants they are investigating. These comments can be reviewed in the Export page
and will be in the final output (either TSV or Excel) when downloaded. This column is by default No comments unless the input
aggregate report has a Comments column pre-specified.
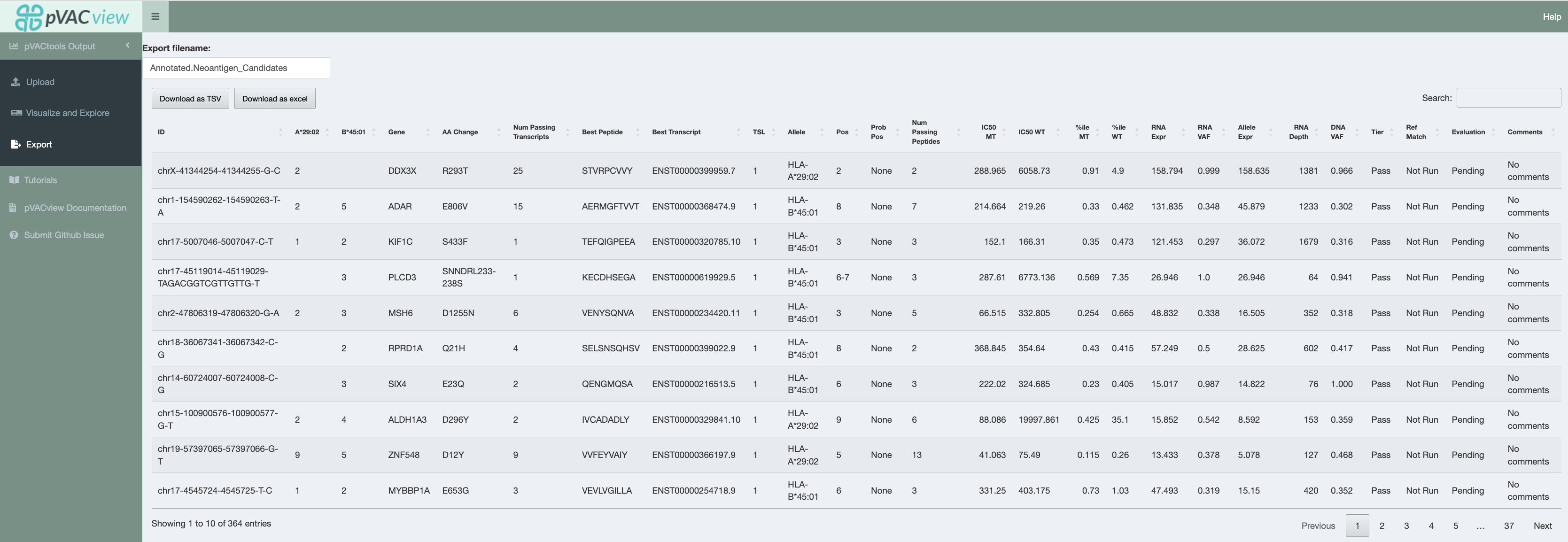
Export¶
When you have either finished ranking your neoantigen candidates or need to pause and would like to save your current evaluations, you can export the current main aggregate report using the export page. (If you are using R studio’s default shiny app browser, you may run into the issue of not being able to properly export depending on your version. This is also why in the prerequisites section, we recommend launching the shiny app in a different web browser)
There are a couple things to note when exporting your current data:
Export filename
By default, your file will be named
Annotated.Neoantigen_Candidates.tsvorAnnotated.Neoantigen_Candidates.xsls. You may want to modify this such that it is specific to your sample.Download as TSV/Excel
We provide two download file types (TSV and Excel). The Excel format is user-friendly for downstream visualization and manipulation. However, if you plan on to continuing editing the aggregate report and would like to load it back into pVACview with the previous evaluations and comments preloaded, you will need to download the file in a TSV format.
This serves as a way to save your progress as your evaluations are cleared upon closing or refreshing the pVACview app.